
سیستم های بحرانی-ایمنی سیستم هایی هستند که ایمنی در آن ها مهم است. ایمنی زمانی فراهم می شود که کلیه توابع و عملیات ها در اینگونه سیستم ها به صورت ایمن عمل کنند. یک سیستم ایمن باید در زمان مورد نیاز در دسترس باشد و با قابلیت اطمینان بالا ( صحیح و بدون خطا ) کارها را انجام دهد و در صورت بروز خطا، خراب نشده و واکنش مناسب به خرابی ها نشان دهد. به سیستم هایی که در صنایع حساس مثل صنایع خودروسازی، راه آهن، مهندسی پزشکی، نفت، گاز و پتروشیمی وجود دارند به علت اینکه در صورت خراب شدن ممکن است خسارات جانی و مالی در پی داشته باشند، ایمنی بحرانی گفته می شود.

برای اینکه بتوانیم در مورد سیستم های بحرانی ایمنی صحبت کنیم ابتدا بایستی بین اصطلاحاتی که تقریبا به جای یکدیگر در روزمره استفاده می شوند، تمایز قائل شویم. برای مثال با درک کردن تمایز بین کلماتی نظیر Fault, Error, Failure که هر سه به معنای خطا هستند، میتوان با تکنیک های مختلف به مقابله با آن پرداخت. همچنین با درک کردن تمایز بین “در دسترس بودن” و “قابلیت اطمینان” میتوان این دو را در سیستم متعادل کرد.
تعریف خطر ، ریسک ، اقدامات کاهشی و ریسک باقیمانده
اصطلاحات خطر ( Hazard ) و ریسک ( Risk ) در استانداردهای مختلف به طور متفاوتی استفاده می شوند. درISO 26262-1 خطر را به عنوان “منبع بالقوه آسیب ناشی از رفتار نامناسب” تعریف می کند در حالی که در IEC 61508 و ISO 14971 همان اصطلاح را به عنوان “منبع بالقوه آسیب” بدون اشاره به رفتار نامناسب تعریف می کند. برای دریافت اطلاعات کامل تر و دسترسی به این متن این استاندارد میتوانید به لینک زیر مراجعه نمایید :
آشنایی با گواهینامه SIL و آموزش استانداردهای IEC 61508 و IEC 61511
به طور خلاصه: کوه یخ خطر است. برخورد کشتی با این کوه یخ ریسک است. یکی از اقدامات کاهش ریسک این است که رنگ کوه زرد باشد تا بهتر دیده شود. اما حتی زمانی که رنگ کوه یخ زرد شود باز هم ریسک باقیمانده زمانی که کشتی در شب یا در مه ممکن است به آن برخورد کند وجود دارد.
به طور کلی من از اصطلاح “خطر” برای یک چیز غیرفعال در محیط استفاده می کنم که ممکن است علت ریسک باشد. ریسک ها خطرات بالقوه ای هستند که با رخدادن یک حادثه خطرناک ( Dangerous event ) به صورت بالفعل درآمده و فعال شده باشند و باعث ایجاد شرایط خطرناک ( Dangerous condition ) شوند. وقتی ریسک شناسایی شد، اگر به اندازه کافی جدی باشد و از اندازه قابل قبول ( Tolerable risk ) بیشتر باشد، باید کاهش یابد. یعنی باید برای کاهش آن اقدام شود.
برای زدن مثالی که به بحث نرم افزارهای امبدد نزدیکتر باشد، حافظه استفاده شده توسط پردازنده میتواند یک خطر باشد. ریسک های مرتبط با آن میتواند شامل موارد زیر باشد:
ریسک : اثرات ثانویه پرتو های کیهانی
که ممکن است باعث چرخش بیتی ( bit-flip ) در حافظه پیکربندی سیستم شود و حالت عملکرد دستگاه را به طور غیرمنتظره ای تغییر دهد و به طور بالقوه موقعیت خطرناکی را بوجود آورد.
یکی از راه های کاهش این ریسک استفاده از بررسی خطا ( Error checking ) و تصحیح ( Correcting ) حافظه ( به طور مخفف ECC ) می باشد. بنابراین خطاها می تواند شناسایی و چرخش های تک بیتی اصلاح شود.
ریسک های باقیمانده شامل این واقعیت است که همه خطاها توسط ECC شناسایی نمی شوند(به ویژه خطاهای 3 بیتی)، برنامه ممکن است به درستی وقفه ( interrupt ) نشان دهنده خطای حافظه را مدیریت نکند و ECC ممکن است حافظه نهان ( cache ) را پوشش ندهد.
ریسک : فرسودگی حافظه
یک برنامه کاربردی ممکن است نشت حافظه ( memory leak ) داشته باشد و به دلیل عدم دسترسی به حافظه اضافی ممکن است به طور غیر منتظره ای از کار بیفتد و به طور بالقوه باعث ایجاد یک موقعیت خطرناک شود.
یکی از راه های کاهش این ریسک این است که هر برنامه کاربردی در هنگام راه اندازی حافظه کافی به صورت استاتیک رزرو کند و هرگز آن را آزاد نکند.
اما باز هم زمانی که شرایطی رخ دهد که هرگز در طول طراحی و آزمایش در نظر گرفته نشده باشد و مقدار حافظه استاتیک تخصیص یافته کافی نباشد، ریسک باقیمانده وجود دارد.
معمولا برای هر خطر چندین ریسک مرتبط و برای هر ریسک چندین روش کاهشی مرتبط وجود دارد.
در دسترس بودن، قابلیت اطمینان و قابلیت اعتماد
هنگامی که یک زیر سیستم نرم افزاری فراخوانی می شود، ممکن است به یکی از این دو روش شکست بخورد: ممکن است اصلا به موقع پاسخ ندهد یا پاسخ بدهد اما پاسخ صحیح نباشد. عدم ارائه پاسخ در مدت زمان مشخص مشکل در دسترس بودن ( Availability ) و ارائه به موقع پاسخ اشتباه را مشکل قابلیت اطمینان ( Reliability ) می نامیم.
افزایش در دسترس بودن عموما قابلیت اطمینان را کاهش می دهد و بالعکس. سروری را در نظر بگیرید که نوعی محاسبه را انجام می دهد. ما میتوانیم با داشتن دو سرور برای انجام محاسبات و مقایسه پاسخ آن ها قابلیت اطمینان سیستم را افزایش دهیم. یک تکنیک خوب این است که:
“هنگامی که فرمول بسیار پیچیده باشد، ممکن است به صورت جبری برای محاسبه به دو یا چند روش مجزا تقسیم شود و دو یا چند مجموعه کارت ساخته شود. اگر از ثابت های یکسانی برای محاسبه هر مجموعه استفاده شود و اگر تحت این شرایط نتایج موافق هم باشد میتوان از صحت آن ها کاملا مطمئن شد”
چارلز بابیج ( Charles Babbage ) سال 1837
هرچند که اضافه کردن سیستم باعث بهبود قابلیت اطمینان می شود اما ماهیت تکراری داشتن باعث کاهش دسترسی می شود، چرا که اگر یکی از دو سرور در دسترس نباشد کل سیستم در دسترس نیست. با توجه به این تضاد بین در دسترس بودن و قابلیت اطمینان، در طول فرآیند طراحی مهم است که بدانیم چه چیزی در آن طراحی باید مورد تاکید قرار گیرد و چگونه باید تعادل حاصل شود. این موضوع در مباحث بعدی بیشتر بررسی شده است.
فکر کردن به این موضوع راحت است که قابلیت اطمینان برای داشتن ایمنی ضروری است حتی به قیمت از دست رفتن دسترسی. اما فکر کردن به سیستمی که در آن در دسترس بودن مهمتر است سخت تر ولی امکان پذیر است. متس هایمدال ( Mats Heimdahl ) یک مثال دور از ذهن از سیستمی را توصیف می کند که در آن هرگونه افزایش در قابلیت اطمینان ایمنی سیستم را کم می کند.
توجه داشته باشید هر چند که کلاینت های یک سرور به طور کلی میتوانند در دسترس بودن یا نبودن سرور را با تنظیم یک Timeout اندازه گیری کنند اما اغلب اندازه گیری قابلیت اطمینان سرور غیر ممکن است. اگر کلاینت ها پاسخ صحیح را می دانستند احتمالا نیازی به فراخوانی سرور نداشتند.
بسیاری از برنامه های تست میتوانند قابلیت اطمینان واقعی را نیز آزمایش کنند و فقط در دسترس بودن را به طور گذرا بررسی می کنند.
در این کتاب من از واژه قابلیت اعتماد ( dependability ) برای ترکیب دو عبارت در دسترس بودن و قابلیت اطمینان استفاده خواهم کرد که برای یک سیستم ترکیب هر دو مهم تر از هر یک به تنهایی می باشد. یک تعریف رایج از قابلیت اعتماد این است که یک سیستم قابل اعتماد است اگر خدماتی را ارائه دهد که به طور موجه قابل اعتماد باشد.
ایمنی عملکرد ( Functional Safety )
ایمنی را می توان به روش های مختلفی تامین کرد. لیزر موجود بر روی یک تجهیز انتقال مخابراتی را در نظر بگیرید: چنین لیزری یک خطر است. یکی از خطرات مرتبط این است که اگر اپراتور فیبر را جدا کند و به فرستنده نگاه کند، ممکن است به چشم آسیب برساند.
یکی از راه های کاهش این خطر، نصب فرستنده رو به پایین و نزدیک به پایین قفسه لیزر می باشد. موقعیتی که امکان تراز کردن چشم با فرستنده را برای اپراتور غیرممکن می کند. این امر با تکیه بر یک سیستم ایمنی غیرفعال ( passive ) ایمن خواهد بود.
یکی دیگر از راه های کاهش خطر این است که نرم افزاری بر کانکتور لیزر نظارت داشته باشد و در صورت حذف فیبر، لیزر را خاموش کند. برای ایمن بودن این سیستم، نیاز به یک بخش فعال ( active ) نرم افزاری وجود دارد تا سیستم به درستی کار کند. نرم افزار باید همیشه کانکتور را زیر نظر داشته باشد و برای جلوگیری از آسیب، لیزر را در عرض چند میلی ثانیه خاموش کند.
دومین مورد از این تکنیک ها بیانگر ایمنی عملکرد می باشد. چیزی است که باید به کار خود ادامه دهد تا سیستم را ایمن نگه دارد.
خطا ( Fault ) اشکال ( Error ) و خرابی ( Failure )
IEEE 24765 بین این سه عبارت به روش زیر تمایز قائل می شود.
یک برنامه نویس ممکن است با تایپ چیزی ناخواسته در یک ویرایشگر، خطایی را به برنامه وارد کند. در واقع خطا یک نقص غیرفعال است و به آن باگ ( bug ) نیز گفته می شود. واژه Fault در کاربردهای سختافزاری “عیب” و در کاربردهای نرمافزاری “خطا” ترجمه میشود.
گاهی اوقات یک خطا ممکن است باعث شود برنامه به گونه ای عمل کند که نتیجه ناخواسته ای ایجاد کند، در واقع خطا باعث ایجاد اشکال شده است.
گاهی اوقات رخ دادن اشکال باعث خرابی سیستم می شود. طبق استاندارد EN 50128 “خرابی زمانی اتفاق می افتد که یک جزء عملیاتی سیستم دیگر نتواند عملکرد صحیح خود را اجرا کند. در واقع خرابی یک اثر قابل مشاهده بیرونی است که از اشکال یا خطای درونی سیستم ناشی می شود. البته همیشه یک اشکال یا خطا لزوما منجر به خرابی سیستم نمی شود.”
نکته مهم در متن بیان شده توسط استاندارد EN 50128 کلمه “گاهی اوقات” است. یک خطا همیشه باعث بروز اشکال نمی شود. مثلا اگر برنامه نویس قصد داشته باشد تا متغیر محلی ( local ) زیر را تایپ کند :
char x[10]
اما به صورت اتفاقی عبارت زیر را تایپ کند :
char x[11]
بعید است که باعث ایجاد اشکال شود مگر اینکه حافظه سیستم بسیار کم باشد. اما در هر صورت این یک خطا می باشد.
اگر برنامه نویس سیستمی ایجاد کند که هر 10 ثانیه یکبار فایلی را باز کند، اما نتواند آن فایل ها را ببندد. این خطا در توصیف گر فایل ( File descriptor ) باعث ایجاد اشکال هر 10 ثانیه یکبار می شود هر چند که این اشکال برای مدتی باعث ایجاد خرابی نمی شود – 90 روز برای کامپیوتری که این متن با آن تایپ شده است طول می کشد تا توصیف گر فایل حداکثر 777.101 فایل باز را اجازه دهد.
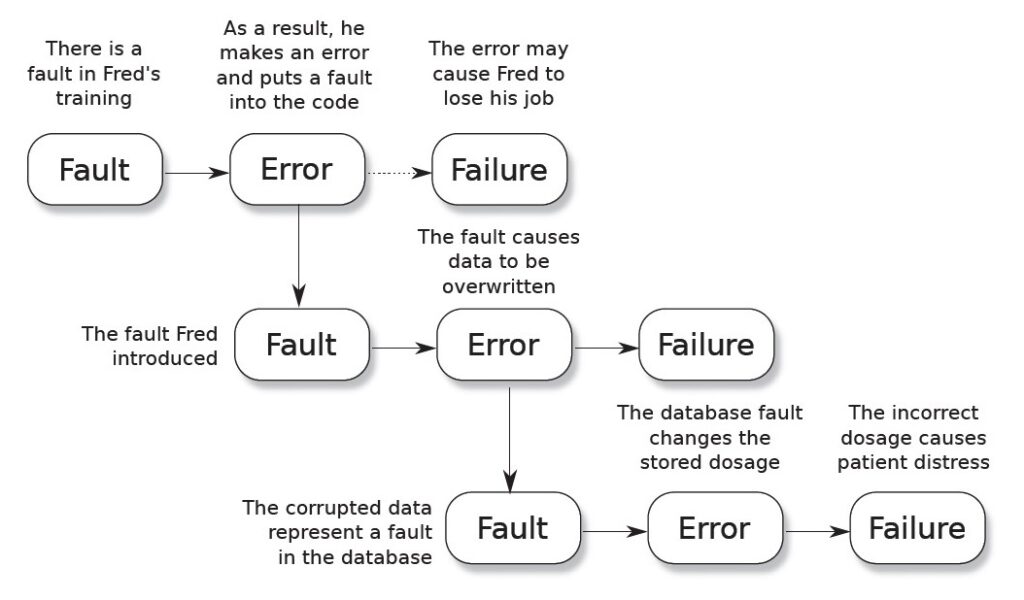
همانطور که در شکل زیر نشان داده شده است، یک اشکال در یک سطح از سیستم ممکن است باعث خطا در سطح دیگر سیستم شود. در این شکل نشان می دهد که یک خطا در سطح آموزشی فرد ( Fred ) باعث شده است که او باگی را در کد ایجاد کند (او با وارد کردن یک خطا در کد باعث بوجود آمدن اشکال می شود) فرد به خاطر این اشتباه شغل خود را از دست می دهد (حداقل تا آنجا که به فرد مربوط می شود) خطا در سطوح مختلف کد ادامه می یابد و باعث خرابی در سیستم کلی می شود.
تمایز بین خطا ها، اشکال ها و خرابی ها به ما این امکان را می دهد که به روش های مختلف با آنها مقابله کنیم. ما می خواهیم تعداد خطا های وارد شده به سیستم را کاهش دهیم و قبل از اینکه به اشکال تبدیل شوند آن ها را شناسایی و حذف کنیم و از به بار آمدن خرابی جلوگیری کنیم و در صورت بروز خرابی، آن را به ایمن ترین شکل ممکن مدیریت کنیم.
هایزن باگ و بور باگ
نیلز بور( Niels Bohr ) یک مدل جامد و توپی شکل از ذرات سازنده اتم را توصیف کرد و جایزه نوبل سال 1922 را برای این کار خود دریافت کرد. ورنر هایزنبرگ ( Werner Heisenberg ) شاگرد و همکار بور، این مدل را تقویت کرد تا اتم ها را بسیار نامشخص کند، به طوری که یک مدل احتمالی از جایی که الکترون ها، نوترون ها و پروتن ها ممکن است باشند را توصیف کرد. این کار باعث شد تا هایزنبرگ در سال 1932 جایزه نوبل را دریافت کند.
ریشه یابی کلمات هایزن باگ و بور باگ نامشخص است، اگر چه جیم گری ( Jim Gray ) از اصطلاح هایزن باگ در سال 1983 استفاده کرد. اعتقاد بر این است که شروع استفاده از این اصطلاحات از اوایل دهه 1980 می باشد.
مدل بور همانطور که در مورد اتم ها وجود دارد، در مورد باگ ها نیز وجود دارد. بور باگ یک باگ به خوبی تعریف شده و جامد با ویژگی هایی است که وقتی کد دیباگ برای یافتن باگ اضافه می شود، تغییر نمی کند. هر بار که یک خط از کد خاص با مقادیر خاصی از متغیرهای ورودی اجرا می شود، سیستم بد رفتار می کند.
در مقابل، هایزن باگ، یک باگ گریزان و گمراه کننده است که ظاهر و ناپدید می شود به طوری که آن را بسیار ناپایدار می کند. هایزن باگ به دلیل مشکلات ریز زمان بندی ایجاد می شود. برای مثال رشته A که روی هسته پردازشی 0 اجرا می شود، کاری را انجام می دهد که روی رشته B در حال اجرا روی هسته پردازشی 1 تاثیر می گذارد، اگر و فقط اگر وقفه ای از نوع C رخ دهد و …
هایزن باگ به عنوان باگ غیر قابل تولید مجدد توسط گروه های انجام آزمایش گزارش می شود: “در هشتمین باری که تست شماره 1243 اجرا شد، سیستم از کار افتاد. از آن زمان تا کنون ما آن تست را بارها انجام دادیم اما در هیچ یک شکستی رخ نداد. هیچ حافظه خالی در دسترس نیست. لطفا باگ را برطرف کنید”
یکی از ویژگی های هایزن باگ این است که یک خطا می تواند منجر به خرابی های مختلف شود و خرابی ها می توانند بسیار دیرتر از زمانی که خطا بوجود آمده بود (و در تکه کدی کاملا متفاوت) رخ دهند. این همان چیزی است که دیباگ کردن را دشوار می کند: آزمایش خرابی ها را شناسایی می کند، در حالی که توسعه دهندگان باید خطاها را برطرف کنند. برای همه خطاها بویژه برای هایزن باگ، مسیر بین خطا و خرابی چند به چند است و این امر ردیابی خطا را با توجه به خرابی بسیار دشوار می کند. شکل زیر را ببینید.
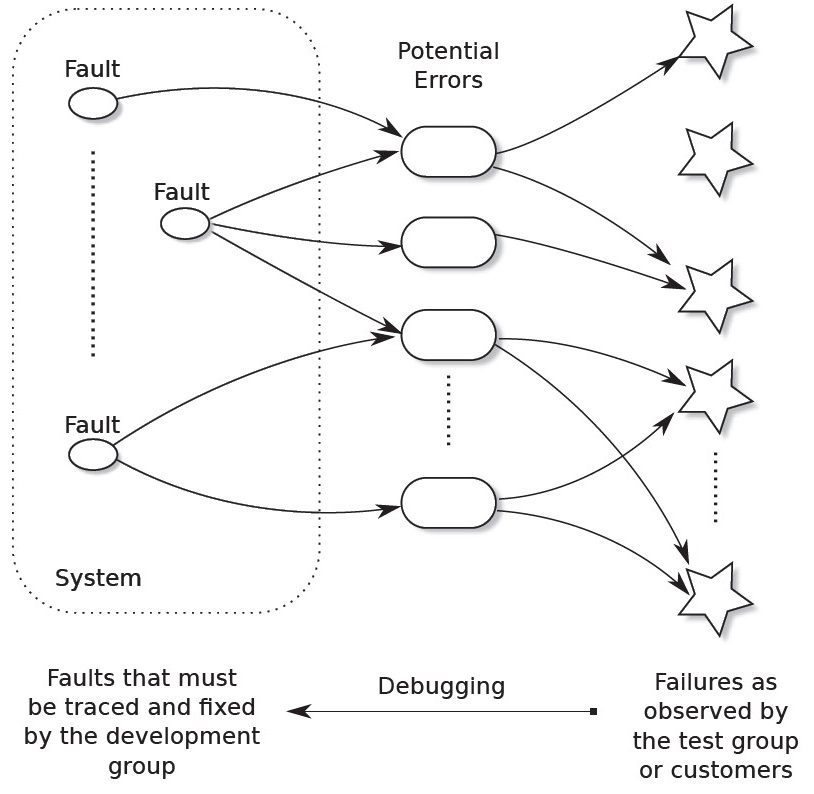
در سطحی که توسط یک آزمایش کننده قابل مشاهده است، به نظر می رسد بسیاری از خرابی ها یکسان هستند. اشکال هایی که باعث خرابی می شوند هم برای آزمایش کننده و هم برای برنامه نویس نامرئی هستند و خطاهای مختلف ممکن است باعث ایجاد اشکال های اساسا یکسان شوند.
جیم گری به این نکته اشاره کرد که کاربران در بقیه زمینه ها به جز در زمینه سیستم های بحرانی ایمنی، هایزن باگ را به بور باگ ترجیح می دهند. یعنی آنها ترجیح می دهند که یک خرابی تصادفی در حدود یک بار در ماه اتفاق بیوفتد تا اینکه هر بار یک دستور خاص در هنگام ورود به زمینه خاص دچار خرابی شود. به همین دلیل تحقیقاتی در مورد تبدیل بور باگ به هایزن باگ انجام شده است. به عنوان مثال، اگر بیشتر از مقدار مورد نیاز برای یک شی، حافظه تخصیص داده شود و حافظه به صورت احتمالی تخصیص داده شود، در این صورت سر ریز حافظه ( Overflow ) به جای بور باگ به هایزن باگ تبدیل می شود.
ماهیت دست نیافتنی هایزن باگ ها رفع آن ها را به ویژه دشوار می کند، و برخی از محققان، به ویژه آندریا بور ( Andrea Borr ) دریافته اند که تلاش برای رفع هایزن باگ ها به طور کلی وضعیت را بدتر از قبل می کند.
برنامه نویسان شوخ طبع اصطلاحات بور باگ و هایزن باگ را در جهت های خنده دار تری گسترش دادند. به عنوان مثال شرودینگ باگ ( Schrodingbug ) که به نام اروین شرودینگر ( Erwin Schrodinger برنده جایزه نوبل در سال 1993 ) نامگذاری شده است. شرودینگ باگ خطایی است که سال ها در کد وجود دارد و هرگز در این زمینه مشکلی ایجاد نکرده است. یک روز در حین خواندن کد، برنامه نویس خبر باگ را دریافت می کند. سپس گزارش های میدانی شروع به سرازیر شدن می کند که این باگ پیدا شده است. دقیقا مانند گربه شرودینگر که ناگهان در محصول ارسال شده بیدار می شود!
این مقاله بخشی از ترجمه کتاب “توسعه نرم افزارهای امبدد برای سیستم های ایمنی بحرانی” اثرک کریس هابز بود.
سرفصل های برخی از مهمترین مطالب این کتاب:
معرفی استانداردهای حوزه ایمنی
یادگیری ماشین و ایمنی عملکرد مورد نظر
تجزیه و تحلیل خطر و ریسک
نحوه استفاده از قطعات دارای گواهینامه یا بدون گواهینامه در یک محصول بزرگتر
برقراری تعادل میان پارامترهای ایمنی در هنگام طراحی معماری
تشخیص بروز خطاها و مدیریت خطاها در سیستم
استفاده از افزونگی سخت افزار و تنوع در سیستم های بحرانی ایمنی
مدل های مارکوف، تجزیه و تحلیل درخت خطا
بدست آوردن نرخ خطا و نرخ خرابی
آشنایی با انواع شبیه سازی های سیستم و طراحی های نیمه رسمی
گرفتن گواهینامه بر اساس طراحی رسمی سیستم
نحوه تایید ( Verification ) و اعتبارسنجی ( Validation ) در یک سیستم بحرانی ایمنی
راهنمایی کدنویسی برای سیستم های امبدد بحرانی ایمنی
معیارهای تست برای دستیابی به حداکثر پوشش کد
استفاده از ابزارهای تحلیل ایستا
تست یکپارچه سازی و تایید کامپایلر
برای سریعتر مشغول به کار شدن در صنایع حساس مثل صنایع خودروسازی، راه آهن، مهندسی پزشکی، نفت، گاز و پتروشیمی، یا برای ارتقای رزومه خود یا برای ایمن کردن محصول امبدد بحرانی-ایمنی شرکت خود و یا برای آشنا شدن با تعداد زیادی از استانداردهای حوزه ایمنی خواندن این کتاب توصیه می شود. این کتاب را از لینک زیر میتوانید تهیه نمایید :

دانلود کتاب توسعه نرم افزارهای امبدد برای سیستم های بحرانی ایمنی





دیدگاهتان را بنویسید